핵심 요약
다나와가 Elasticsearch 3TB 규모 인덱스의 재색인 방법과 과정에서 직면한 이슈 해결과 현재 상태를 공유합니다.
구현 방법
- Replica는 reindex 완료 후에 생성하지 않는 것이 좋다. 초기 IO 부하를 줄이기 위함.
- refresh_interval를 -1로 설정하여 재색인 중 검색 차단 및 처리 속도 향상.
- 배치 사이즈를 조정: reindex의 size 파라미터를 적절히 증가시켜 색인 효율을 높이고, 환경에 맞춘 최적 지점을 탐색.
- 기본값은 1,000이며, 예시로 5,000까지 시도 가능.
- 프라이머리 샤드 수를 조정: 샤드 수가 색인 속도에 비례하므로 시스템 자원과 목표에 맞춰 증가/감소를 실험.
- 트러블슈팅
- es_rejected_execution_exception: 큐 자원 부족으로 발생하므로 target_time과 wait_time를 활용한 쓰로틀링으로 완화.
- 리사이징 이후 해당 현상은 감소하거나 발생하지 않게 됨.
- circuit_breaker_exception: 메모리 부하로 인한 이슈로, 작업 시간대 변경이나 옵션 조정으로 부하를 낮춤.
- replica 생성 시 속도 제한 필요 시 다음과 같이 설정 권고:
curl -XPUT localhost:9200/_cluster/settings -d '{ "persistent" : { "indices.recovery.max_bytes_per_sec": "128mb" } }'
- 정리: 대용량 인덱스 색인 시 발생 가능한 문제와 해결 방안을 시스템 상황에 맞춰 적용.
주요 결과
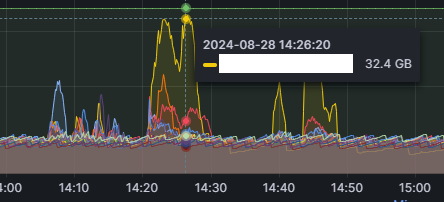
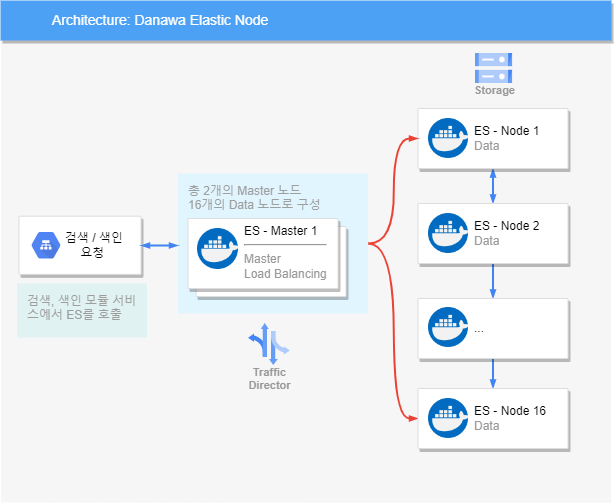
- 현재 시스템은 약 3.X TB의 데이터를 레플리카 포함하여 10~11시간에 색인하는 구조로 운영되며, 노드는 총 18개(2 마스터 + 16 데이터), ES 7.8.1 기준.
- 재색인 구성에서 Replica 생성 시점을 재색인 완료 후로 옮기고, refresh를 꺼며 배치 사이즈를 조정하는 등 조치를 통해 안정성과 효율을 확보하는 방향으로 개선 시도.
- es_rejected_execution_exception 및 circuit_breaker_exception에 대한 트리거 관리 및 속도 제어를 통해 문제 발생 빈도를 감소시키는 효과를 관찰.